Race condition
Een race condition is de toestand van een elektronisch, software- of ander systeem waarbij het wezenlijke gedrag van het systeem afhankelijk is van de volgorde of timing van andere oncontroleerbare gebeurtenissen. Dit kan leiden tot onverwachte of inconsistente resultaten. Er is sprake van een bug als een of meer van de mogelijke gedragingen ongewenst zijn.
De term race condition werd al in 1954 gebruikt, bijvoorbeeld in het proefschrift van David Huffman "The synthesis of sequential switching circuits".
Race conditions kunnen vooral voorkomen in logische schakelingen of multithreaded of gedistribueerde softwareprogramma's. Door wederzijdse uitsluiting te gebruiken, kunnen race conditions in gedistribueerde softwaresystemen worden voorkomen.
In de elektronica
Een typisch voorbeeld van een raceconditie kan ontstaan wanneer een logische poort signalen combineert die vanuit dezelfde bron verschillende paden hebben afgelegd. De ingangsspanningen van de poort kunnen op iets verschillende tijdstippen veranderen als reactie op een verandering in het bronsignaal. Het is mogelijk dat de uitvoer gedurende een korte periode overgaat naar een ongewenste toestand, om vervolgens terug te keren naar de te verwachten toestand.
Bepaalde systemen kunnen dergelijke storingen wel tolereren, maar als deze uitvoer bijvoorbeeld als kloksignaal fungeert voor andere systemen die geheugen bevatten, kan het gedrag van het systeem snel afwijken van het ontworpen gedrag (in feite wordt de tijdelijke storing een permanente storing).
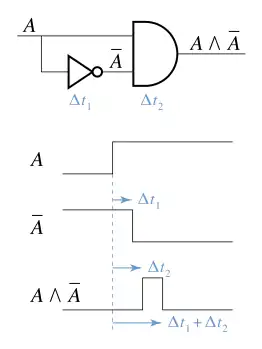
Beschouw bijvoorbeeld een AND-poort met twee ingangen die wordt gevoed met de volgende logica: Een logisch signaal op één ingang en de negatie ervan, (de ¬ is een Booleaanse ontkenning) op een andere zal in theorie nooit een waarde 1 opleveren: .




Als er echter veranderingen optreden in de waarde van die iets langer duren om aan te komen op de tweede ingang dan tot de eerste wanneer verandert van false naar true, dan volgt er een korte periode waarin beide ingangen true zijn, en dus zal de uitgang van de poort ook true zijn.
Een praktisch voorbeeld van een race condition kan ontstaan wanneer logische schakelingen worden gebruikt om bepaalde uitgangen van een teller te detecteren. Als niet alle bits van de teller precies tegelijkertijd veranderen, kunnen er tussenliggende patronen ontstaan die tot valse matches kunnen leiden.
Oplossingen
Ontwerptechnieken zoals Karnaugh-diagrammen moedigen ontwerpers aan om race conditions te herkennen en te elimineren voordat ze problemen veroorzaken. Vaak kan logische redundantie worden toegevoegd om bepaalde soorten race conditions te elimineren.
Naast deze problemen kunnen sommige logische elementen metastabiele toestanden bereiken, wat voor nog meer problemen zorgt voor ontwerpers van schakelingen.
In software
Een race condition kan ontstaan in software wanneer een computerprogramma meerdere codepaden tegelijk uitvoert. Als de verschillende codepaden een andere tijd in beslag nemen dan verwacht, kunnen ze in een andere volgorde worden afgewerkt dan verwacht. Dit kan leiden tot softwarefouten vanwege onverwacht gedrag. Er kan ook een race ontstaan tussen twee programma's, wat tot veiligheidsproblemen kan leiden.
Kritieke race conditions veroorzaken ongeldige uitvoering en softwarefouten. Kritieke race conditions ontstaan vaak wanneer processen of threads afhankelijk zijn van een gedeelde status. Bewerkingen op gedeelde toestanden worden uitgevoerd in kritieke secties die elkaar wederzijds moeten uitsluiten. Als deze regel niet nageleefd wordt, kan de gedeelde status corrupt geraken.
Het kan lastig zijn om een race condition te reproduceren en te debuggen, omdat het eindresultaat niet-deterministisch is en afhankelijk is van de relatieve timing tussen interfererende threads. Problemen van deze aard kunnen verdwijnen wanneer men in debugmodus werkt, extra logging toevoegt of een debugger koppelt. Een bug die op deze manier verdwijnt tijdens het debuggen, wordt vaak een "Heisenbug" genoemd. Het is daarom beter om race-omstandigheden te vermijden door een zorgvuldig softwareontwerp.
Voorbeeld
Veronderstel dat twee threads elk de waarde van een globale gehele variabele met 1 verhogen. Idealiter zou de volgende volgorde van handelingen plaatsvinden:
| Thread 1 | Thread 2 | Gehele waarde | |
|---|---|---|---|
| 0 | |||
| lees waarde | ← | 0 | |
| verhoog waarde | 0 | ||
| schrijf weg | → | 1 | |
| lees waarde | ← | 1 | |
| verhoog waarde | 1 | ||
| schrijf weg | → | 2 |
In het bovenstaande geval is de eindwaarde, zoals verwacht, 2. Als de twee threads echter gelijktijdig worden uitgevoerd zonder vergrendeling of synchronisatie (via semaforen), kan de uitkomst van de bewerking onjuist zijn. De onderstaande alternatieve volgorde van bewerkingen illustreert dit scenario:
| Thread 1 | Thread 2 | Gehele waarde | |
|---|---|---|---|
| 0 | |||
| lees waarde | ← | 0 | |
| lees waarde | ← | 0 | |
| verhoog waarde | 0 | ||
| verhoog waarde | 0 | ||
| schrijf weg | → | 1 | |
| schrijf weg | → | 1 |
In dit geval is de eindwaarde 1 in plaats van het verwachte resultaat 2. Dit komt doordat de incrementele bewerkingen elkaar hier niet uitsluiten. Wederzijds exclusieve bewerkingen zijn bewerkingen die niet kunnen worden onderbroken tijdens de toegang tot een bepaalde bron, bijvoorbeeld een geheugenlocatie.
Bestandssystemen
Twee of meer programma's kunnen met elkaar in conflict komen bij hun pogingen om een bestandssysteem te wijzigen of er toegang toe te krijgen, wat kan leiden tot datacorruptie of verhoogde privileges.
Een veelgebruikte oplossing is het vergrendelen van bestanden. Een meer omslachtige oplossing is het systeem zo te organiseren dat één uniek proces (dat bijvoorbeeld een daemon draait) exclusieve toegang heeft tot het bestand, en alle andere processen die toegang moeten hebben tot de gegevens in dat bestand dit alleen via interprocescommunicatie met dat ene proces kunnen. Hiervoor is synchronisatie op procesniveau nodig.
Een andere vorm van race condition ontstaat in bestandssystemen, waarbij niet-gerelateerde programma's elkaar kunnen beïnvloeden doordat ze plotseling alle beschikbare bronnen, zoals schijfruimte, geheugenruimte of processorcycli, gebruiken. Software die niet zorgvuldig is ontworpen om deze race condition te voorzien en af te handelen, kan onvoorspelbaar worden. In een systeem dat heel betrouwbaar lijkt, kan een dergelijk risico lange tijd over het hoofd worden gezien. Maar uiteindelijk kunnen er zoveel gegevens verzameld worden of kan er zoveel andere software worden toegevoegd dat grote delen van een systeem ernstig instabiel worden.
Een voorbeeld hiervan deed zich voor bij het bijna-verliezen van de Marsrover "Spirit" kort na de landing, wat gebeurde als gevolg van verwijderde bestandsvermeldingen waardoor de bibliotheek van het bestandssysteem zelf alle beschikbare geheugenruimte in beslag nam.
Een oplossing is dat de software alle benodigde bronnen aanvraagt en reserveert voordat een taak wordt gestart. Als dit verzoek mislukt, wordt de taak uitgesteld. Zo worden de vele punten vermeden waarop de fout had kunnen optreden. Als alternatief kan elk van deze punten worden uitgerust met foutbehandeling, of kan het succes van de hele taak achteraf worden geverifieerd, voordat er verder wordt gegaan.
Een meer gangbare aanpak is eenvoudigweg te controleren of er voldoende systeembronnen beschikbaar zijn voordat men een taak start. Dit is echter mogelijk niet voldoende, omdat in complexe systemen de acties van andere actieve programma's onvoorspelbaar kunnen zijn.
- Dit artikel of een eerdere versie ervan is een (gedeeltelijke) vertaling van het artikel Race condition op de Engelstalige Wikipedia, dat onder de licentie Creative Commons Naamsvermelding/Gelijk delen valt. Zie de bewerkingsgeschiedenis aldaar.